Microsoft Excel | UNIQUE関数の使い方
この記事では、Microsoft Excelで使用できるUNIQUE関数の使い方を解説します。
UNIQUE関数の2つの機能
UNIQUE関数には2つの機能があります。
- 重複を削除した結果を返す
- 重複のないデータを返す
それぞれ詳しく見ていきましょう。
重複を削除した結果を返す
ひとつ目は、重複を削除した結果を返すものです。
例を挙げます。
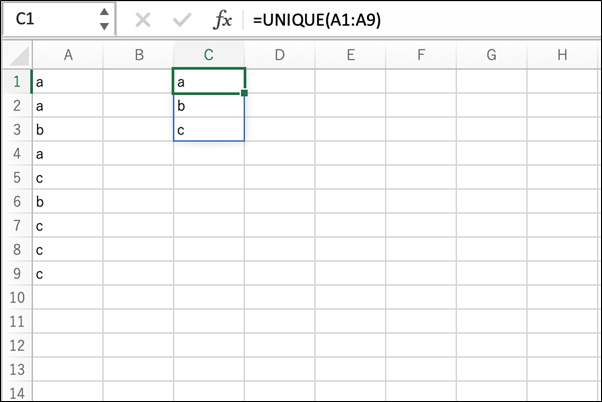
A1からA9のそれぞれのセルに、「a」「b」「c」いずれかの文字が入力されています。
そして、C1セルに、「=UNIQUE(A1:A9)」という関数が入力されており、それが、「a」「b」「c」という3つの結果を返しています。
A1からA9に入力されているのは、「a」が3つ、「b」が2つ、「c」が4つと、それぞれ複数ありますが、
それらの重複したデータを削除した結果である、「a」「b」「c」という結果がUNIQUE関数から得られています。
重複のないデータを返す
次は、重複のないデータを返す機能についてです。
こちらも例を挙げます。
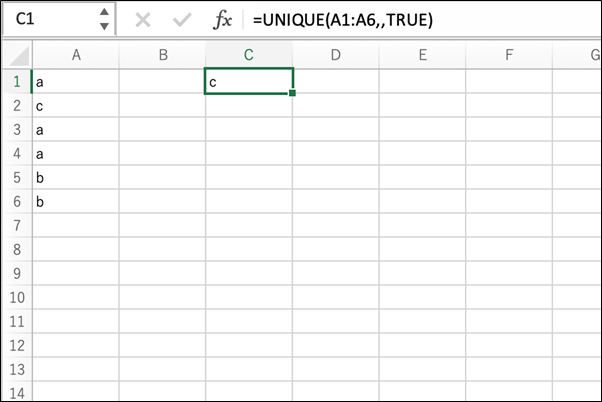
この例では、A1からA6セルの範囲に、「a」「b」が複数、「c」がひとつだけ入力された状態となっています。
そして、C1に入力されたUNIQUE関数「=UNIQUE(A1:A6,,TRUE)」が、「c」という結果を返しています。
※先ほどの関数と違い、第3引数に「TRUE」を指定しています。
「a」「b」は複数あるためこの関数の結果には含まれず、ひとつしかない「c」だけが返されています。
UNIQUE関数の引数
UNIQUE関数は3つの引数を取ります。
- 配列
- 列の比較
- 回数指定
第一引数:配列
第一引数は「配列」です。
これは、どの範囲から結果を返すかを指定するものです。
ここで指定した範囲から、重複を削除した結果(または、重複のないデータ)を探し、結果を返します。
上の例では、1列に全てのデータが含まれていましたが、複数列にまたぐデータを指定することも可能です。

第二引数:列の比較
第二引数は「列の比較」です。
これは、「FALSE」を指定すると行の重複を判定し、「TRUE」を指定すると列の重複を判定する、というものです。
指定しない場合は、FALSEを指定したのと同様になり、行の重複を判定します。
行の重複と列の重複との違いがわかる例を挙げます。
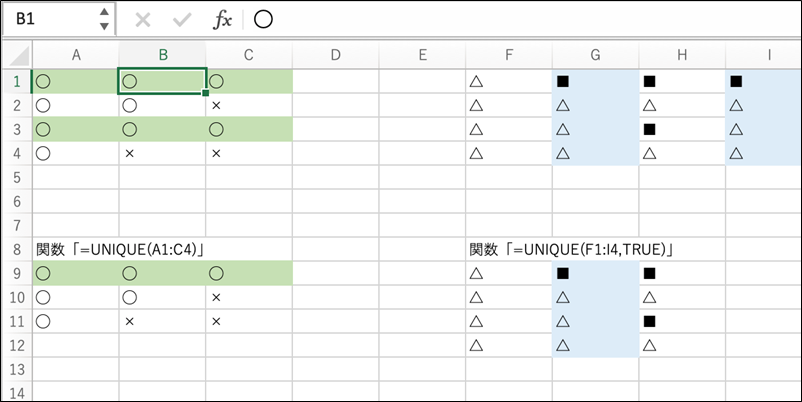
左の関数は行の重複を判定しています。
全ての値が同じ行(1行目と3行目)が同一と判断され、その重複を除いた結果が返されています。
一方で、右側では、全ての値が同じ列(G列とI列)が同一と判断され、その重複を除いた結果が返されています。
このように、第二引数に「TRUE」を指定することで、行ではなく、列の重複を判定することが可能になります。
第三引数:回数指定
第三引数は「回数指定」です。
これは、「重複を削除した結果を返す」か「重複のないデータを返す」かを選択するための引数です。
「FALSE」を指定すると「重複を削除した結果を返す」となり、「TRUE」を指定すると「重複のないデータを返す」となります。
指定しない場合は、FALSEを指定したのと同様になり、「重複を削除した結果を返す」となります。
冒頭の「UNIQUE関数の2つの機能」では、こちらの引数によって、2つの機能を切り替えていました。
改めて違いがわかる例を挙げます。
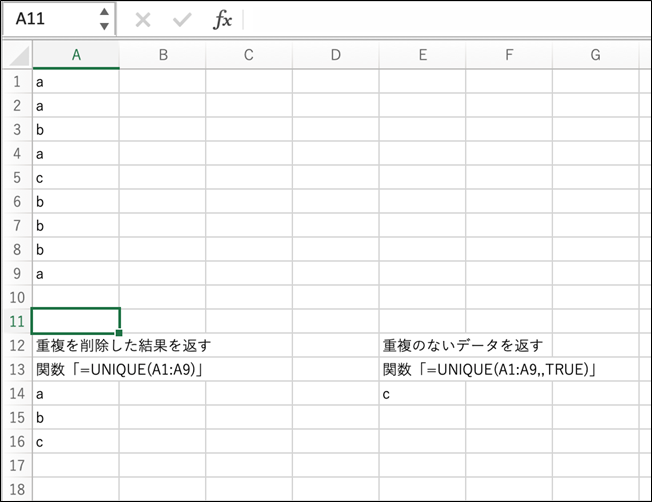
左の例では、「重複を削除した結果を返す」を指定しており、重複を除いた「a」「b」「c」の3つの値が返っています。
右の例では、「重複のないデータを返す」を指定しているため、元のデータに重複のない「c」だけが返されています。
どういう時に使えるのか
ここからは、UNIQUE関数の使い所について考えてみます。
関数の結果そのものが欲しい場合
まず考えられるのは、UNIQUE関数の結果そのものが目的の場合です。
何かのデータがあり、その中の重複を削除した結果が欲しいといったケースや、重複のないデータを抽出したいケースでは、UNIQUE関数を利用するのが良いでしょう。
当然といえば当然ですが、UNIQUE関数だけで目的が達せられるのであれば、UNIQUE関数を使うのが良いということですね。
何種類のデータがあるかを数えたい場合
重複を含んだデータが多数あり、それらが何種類あるかを数えたい場合も、UNIQUE関数を使うのが適していると言えるでしょう。
例えば、「a」が100件、「b」が150件、・・・、「z」が50件というようなデータが存在したとして、それらの重複を除いた「a」〜「z」の「26種類」という結果が欲しい場合には、UNIQUE関数を使用するのが適しているといえます。
SQLに馴染みのある方であれば、「COUNT(DISTINCT 〜)」のようなことをしたい場合と考えていただいてもいいかもしれません。
以下のような関数を書くことで、何種類のデータがあるかを数えることができます。
=COUNTA(UNIQUE(〜))
※「〜」の部分は、適宜引数を記入してください。
似たような機能との比較
ここまでUNIQUE関数の使い所を書いてみましたが、あまりUNIQUE関数を使うところというのは多くありません。
それは、重複したデータを扱うことのできる機能が他にも存在するためです。
ここからは、似たような他の機能と比べてUNIQUE関数にはどんな特徴があるのかをみていきます。
ピボットテーブル
ひとつめの機能はピボットテーブルです。
UNIQUE関数と比べると、何より機能が豊富です。
重複したデータを扱う場合であっても、例えば、それぞれのデータの件数を数えたい場合や、件数が10件以上のデータに絞りたいといったように、より複雑な条件での作業が必要であれば、ピボットテーブルを使う方が適しています。
UNIQUE関数を使用してデータの種類を求め、COUNTIF関数やCOUNTIFS関数を使用することで、それぞれのデータの件数を算出することも可能です。
しかし、そのようなことをするのであれば、ピボットテーブルを使う方が、より簡単に、直感的な操作でできます。
COUNTIF関数、COUNTIFS関数
次は、COUNTIF関数、COUNTIFS関数との比較です。
COUNTIF関数やCOUNTIFS関数を使えば、UNIQUE関数で行った「重複を削除した結果」「重複のないデータ」を探すことは可能です。
「重複を削除した結果」を探すには、各データに対し、COUNTIF関数を使って、自身と同一のデータが、以降の行に何件あるかをカウントした結果を付与します。
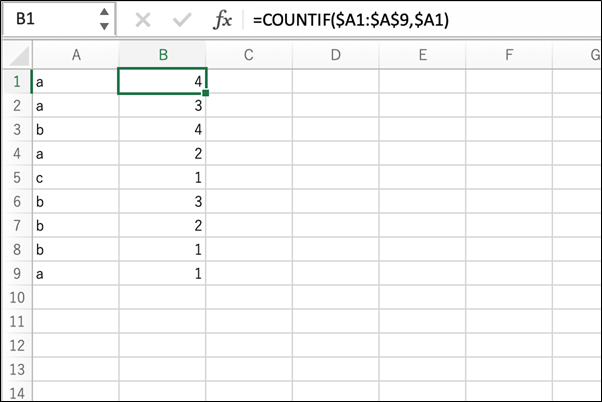
付与した列から結果が「1」になっている行を抽出すれば、「重複を削除した結果」を得ることができます。
関数の解説
サンプルでは、B1セルに「=COUNTIF($A1:$A$9,$A1)」と入力しています。
ポイントとなるのは、第一引数の$A1の行が相対参照になっていて、同じく第一引数の$A$9の行が絶対参照となっているところです。
$A1の行を相対参照にしていることで、B2、B3に入力されている関数が、それぞれA2、A3以降のセルを参照することができます。
つまり、参照する範囲を何行目からにするか、というのを、各行に合わせて変化させられるということです。
また、$A$9が絶対参照になっていることで、何行目まで参照するか、というのを9行目に固定することができます。
また、「重複のないデータ」を探すには、各データに対し、COUNTIF関数を使って、自身と同一のデータがデータ全体に何件あるかをカウントした結果を付与します。
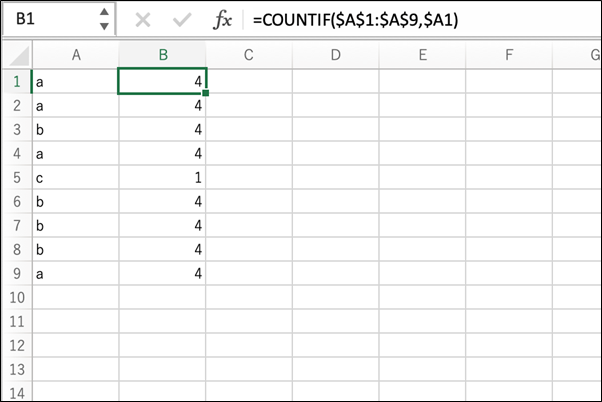
こちらも同様に、付与した列から結果が「1」になっている行を抽出すれば、「重複を削除した結果」を得ることができます。
関数解説
こちらの例では、セルA1に入力されている関数は「=COUNTIF($A$1:$A$9,$A1)」となっています。
先ほどの例とは対照的に、第一引数の$A$1、$A$9は、どちらも絶対参照となっています。
これにより、全ての行について、A1からA9の範囲を参照することができるようになっています。
このように、UNIQUE関数を使ってできることは、COUNTIF関数やCOUNTIFS関数を使っても実現可能です。
では、COUNTIF関数やCOUNTIFS関数を使う方法の特徴はなんでしょうか。
それは、元のデータに対して、COUNTIF関数やCOUNTIFS関数の結果を付与する必要があるという点です。
UNIQUE関数であれば、元のデータ全体を参照して目的の結果を返すことができますが、COUNTIF関数やCOUNTIFS関数を使用する場合は、各々のデータに対して関数を入力する必要があります。
そのため、元のデータに対して列を追加することができない場合は、COUNTIF関数やCOUNTIFS関数を使う方法は適用しない方が良いでしょう。
また、データの件数が多い場合、関数の計算処理が重くなるというデメリットもあります。
PCのスペックやデータ量にもよりますが、計算処理が重くなりすぎると、Excelが最後まで計算を終えることができない可能性もあります。
重複の削除
最後に「重複の削除」と比較してみましょう。
これは、UNIQUE関数の「重複を削除した結果を返す」と同じような機能になります。
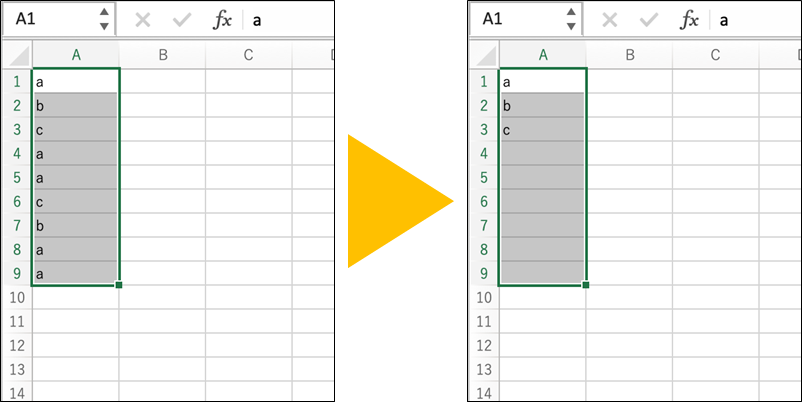
「重複の削除」機能は、「データ」タブの「重複の削除」ボタンから起動できます。「重複の削除」ボタンを押下するとウィンドウが表示されるので、そこで重複を判定する列を選択してからOKボタンを押下することで、重複したデータを削除した結果を得られます。
「重複の削除」の特徴は、重複を削除する前のデータが残らないことです。
UNIQUE関数であれば、UNIQUE関数の参照先のデータは元のまま残ります。
しかし、「重複の削除」を使用すると、元のデータが削除された上で、重複が削除されたデータだけが残ることになります。
おわりに
本記事では、UNIQUE関数の使い方について解説しました。
「重複を削除した結果を返す」「重複のないデータを返す」という2つの機能があったり、他にも似たような機能があったりと、若干使い所が難しい面もありますが、それぞれの機能をきちんと理解して使い分けることができれば便利な関数だと思います。
ぜひ、活用してみてください。

